本博文是我对计算机系统中的缓存做的备忘笔记,参考资料来自于互联网。
Background
Memory Hierarchy
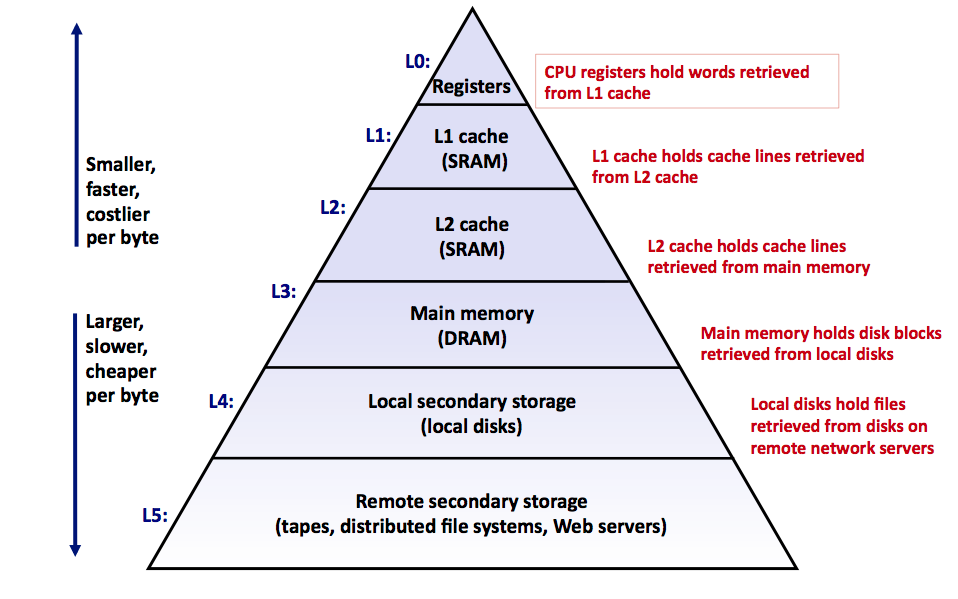
众所周知,对于不同的存储设备,更高的性能意味着更高的成本和更小的容量。随着 CPU 越做越快,CPU 和主存之间的速度差距正在不断扩大。好在,软件的局部性原理 拯救了这一切,在现代计算机体系中通过 Memory Hierarchy 的设计,使得系统在性能、成本和制造工艺之间作出取舍,从而达到了一个平衡。
下图是现在可以看到的常见的存储器层次机构:
Principle of Locality
程序访问的局部性原理指的是,内存中某个地址被访问后,短时间内还有可能继续访问这块地址。内存中的某个地址被访问后,它相邻的内存单元被访问的概率也很大。
程序访问的局部性包含两种:
- 时间局部性:某个内存单元在较短时间内很可能被再次访问
- 空间局部性:某个内存单元被访问后相邻的内存单元较短时间内很可能被访问
出现这种情况的原因很简单,因为程序是指令和数据组成的,指令在内存中按顺序存放且地址连续,如果运行一段循环程序或调用一个方法,又或者再程序中遍历一个数组,都有可能符合上面提到的局部性原理。
那既然在执行程序时,内存的某些单元很可能会经常的访问或写入,那可否在CPU和内存之间,加一个缓存,CPU在访问数据时,先看一下缓存中是否存在,如果有直接就读取缓存中的数据即可。如果缓存中不存在,再从内存中读取数据。
事实证明利用这种方式,程序的运行效率会提高90%以上,这个缓存也叫做高速缓存Cache。
Big Picture
在深入了解 Cache 的技术细节之前,我们可以先看看关于 Cache 在现代计算机系统中的 big picture。如下图所示,ALU 不是直接和主存相连,所有的 load 和 store 通过 Cache 完成,Cache 是 CPU 芯片组成的一部分。

随着计算机系统的发展,Cache 不仅仅只有一层,可能被分为多层。于此同时,人们发现,将指令的 Cache 和 数据的 Cache 分开可以获得更大的系统增益。而且,CPU也从单核单处理器逐渐发展到多核多处理器,所以一个现代的计算机系统中,Cache 的组成方式可能如下图所示:

在这个图中,只显示了一个处理器(Processor),处理器中有四个核(Core),每个 Core 会有自己的L1数据缓存和L1指令缓存,也有自己统一的 L2 缓存。四个核之间会共享 L3 缓存,L3 缓存和主存直接沟通。
General Cache Organization
Cache 是以 缓存行(Cache Line) 为基本组织单位的,下图是一个通用的缓存组织结构。

假设内容容量是 M,内存物理地址为 m 个bit。CPU 在访问缓存时,物理地址会被解析成如下的格式

这里,有如下的关系
参数具体意义如下:一个 Cache 被分成 S 个 set,每个 set 有 E 路 Cache Line。在一个 Cache Line 中,有 B 个字节的存储单元。所以,在一个内存地址中,中间的 s 个 bit 决定了该寻址单元被映射到哪个 set,而最低的 b 个 bit 决定了该单元在一个缓存行中的偏移量。tag 是内存地址的高 t 个 bit,因为可能有多个内存地址映射到同一个 Cache Line 中,所以用 tag 来校验该 Cache Line 是否是 CPU 要访问的内存单元。
上面是从内存地址的角度看访问 Cache 时候的地址参数解析,对应到实际的 Cache Line 的组成,可以看第一张图。可以看到,对于每一个 Cache Line,除了 tag 用来校验是否是 CPU 要访问的内存单元,还有一个 valid bit 来确认该缓存行是否有效,然后就是一个含有 $B = 2^b$ 个字节的 Cache Block。在目前的 x86 CPU 的 Cache Line 中,一般都是 64 字节的。
当 tag 和 valid 校验成功时,我们称为 Cache Hit,这时就可以将cache中的单元取出,放入到 CPU 中的寄存器。
当 tag 或 valid 校验失败时,说明要访问的内存单元并不在cache中,需要去内存中或者下一级的 Cache 中取出,这就是 Cache Miss。当不命中的情况发生时,系统就会从内存中或者下一级缓存中取得该单元,将其装入cache中,与此同时也放入CPU寄存器中,等待下一步处理。
下图是一个典型的 Cache Read 的流程

Cache Implement Details
根据上面参数 E 的不同选择,可以把 Cache 到 Memory 的映射分为以下几种类型
- 全相联(Fully Associative)
- $s = 0$,每个内存块数据可以映射到任意缓存行中
- 直接映射(Direct Mapped),也称单路组相连(Single Way Set Associative)
- $E = 1$,每个内存块数据只能映射到固定的缓存行中
- 多路组相联(N Way Set Associative)
- $E = N$, 每个内存块数据可以映射到固定 set 的任意缓存行中
Fully Associative Cache
全相联把内存方位两个字段,tag 和 offset,没有了 set index 的字段。
在访问数据时,直接根据内存地址中的 tag,去遍历对比每一个缓存行,直到找到 tag一致的缓存行,然后访问其中的数据。
如果遍历完所有的缓存行之后,没有找到一致的tag, 那么就会从内存中获取数据,然后找到空闲的缓存行,直接写入tag和 数据即可。
全相联意味着主存中的数据块可以出现在任意一个缓存行中。这种方式下替换算法(Replacement Policy)有最大的灵活度,也意味着可以有最低的 Cache Miss Rate。但是因为没有索引可以使用,检查一个缓存行是否命中需要在整个 Cache 范围内搜索,这带来了查找电路的大量延时。因此只有在缓存极小的情况下才有可能使用这种映射方式。

Direct Mapped Cache
直接映射是一种多对一的映射关系。在这种映射下,主存中的每一个数据块只能有一个缓存行与之对应。可能有多个主存中的数据块被映射到统一个缓存行,但是每一个数据块只能被映射到确定的缓存行。
在 1990 年代初期,直接映射是当时最流行的机制。但是随着 CPU 主频的提高,直接映射机制正在逐渐退出舞台。
直接映射最大的问题在于,每个数据块在哪个缓存行是确定的,没有替换策略(Replacement Policy)。如果两个数据块被映射到同一个缓存行时,它们会不停的把对方替换出去。由于严重的冲突,频繁刷新 Cache 会造成大量的延时,而且未能有效利用程序运行期所具有的时间局部性。这样导致了缓存命中率(cache miss rate)明显提高。
下图是一个Memory 为 16Kbytes, Cache Line 为 4bytes 的直接映射缓存例子。

Set Associative Cache
组相联映射结合了以上两种映射方式的优点。具体的方法就是
- 首先通过 set index 来确认数据块应该放在哪一个 set 中
- 确认到 set 之后,通过 cache 替换策略(Replacement Policy)来确定到底放在组中的那个缓存行

Cache Replacement Policy
Cache容量比内存小,所以内存数据映射到Cache时,必然会导致Cache满的情况,那之后的内存映射要替Cache中的哪些行呢?这就需要制定一种策略。
常见的替换算法有如下几种:
- 先进先出算法(FIFO):总是把最早装入Cache的行替换掉,这种算法实现简单,但不能正确反映程序的访问局部性,命中率不高
- 最近最少使用算法(LRU):总是选择最近最少使用的Cache行替换,这种这种算法稍微复杂一些,但可以正确反映程序访问的局部性,命中率最高
- 最不经常使用算法(LFU):总是替换掉Cache中引用次数最少的行,与LRU类似,但没有LRU替换方式更精准
- 随机替换算法(Random):随机替换掉Cache中的行,与使用情况无关,命中率不高
现实使用最多的是最近最少使用算法(LRU)进行Cache行的替换方案,这种方案使得缓存的命中率最高。
Cache in Real World
可以通过如下的方式查看。
1 | ----- 如果启动时间比较短,可以通过如下方式查看 |
另外,由专门针对 x86 信息的程序,也就是 x86info ,可以直接安装对应的包。
注意,现在多数的 CPU 采用的是超线程,也就是说对于一个物理核来说,对于内核看到的是两个,而实际的物理核是一个。
另外,在 /sys/devices/system/cpu/ 中包含了一些相关的指标,例如。
1 | ----- 查看cpu0的一级缓存中的有多少组 |
通过类似 lscpu 查看到对应 CPU0 的一级缓存大小是 32K ,包含了 64 个组 (sets),每组有 8 ways,则可以算出每一个 way (也就是 Cache Line) 的大小是 32*1024/(64*8)=64 。
可以通过如下方式查看。
1 | cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size |
这里是 Intel Core i7 L1数据缓存的实际例子

Cache Write
试想,如果CPU想要修改某个内存的数据,这块内存的数据刚好在Cache中存在,那么是不是要同时更新Cache中的数据?对于写入的数据,如何保证Cache和内存数据的一致性?
Cache Write Hit
- Write through
- 在写操作时,如果Cache命中,则同时写Cache和内存。
- Write back
- 在写操作时,如果Cache命中,则只更新Cache而不更新内存。
- 所以每一个 Cache Line需要有一个 dirty bit
Cache Write Miss
- Write Allocate
- 先更新内存数据,然后再写入空闲的Cache行中,保证Cache有数据,提高了缓存命中率,但增加了写入Cache的开销
- No Write Allocate
- 只更新内存数据,不写入Cache,只有等访问不命中时,再进行缓存写入
关于缓存一致性的问题,可以参考我的另一篇博文 Cache Coherency,此处不再赘述。
Cache Friendly Code
针对缓存的这种特殊的结构,作为程序猿,如果一不小心,可能会带来重大的性能问题。
一些典型的案例可以参考我的另一篇博文 Cache Friendly Code,此处不再赘述。
Reference
- https://lwn.net/Articles/252125/
- http://hedengcheng.com/?p=648
- CMU 15213 Cache Memories Slide

